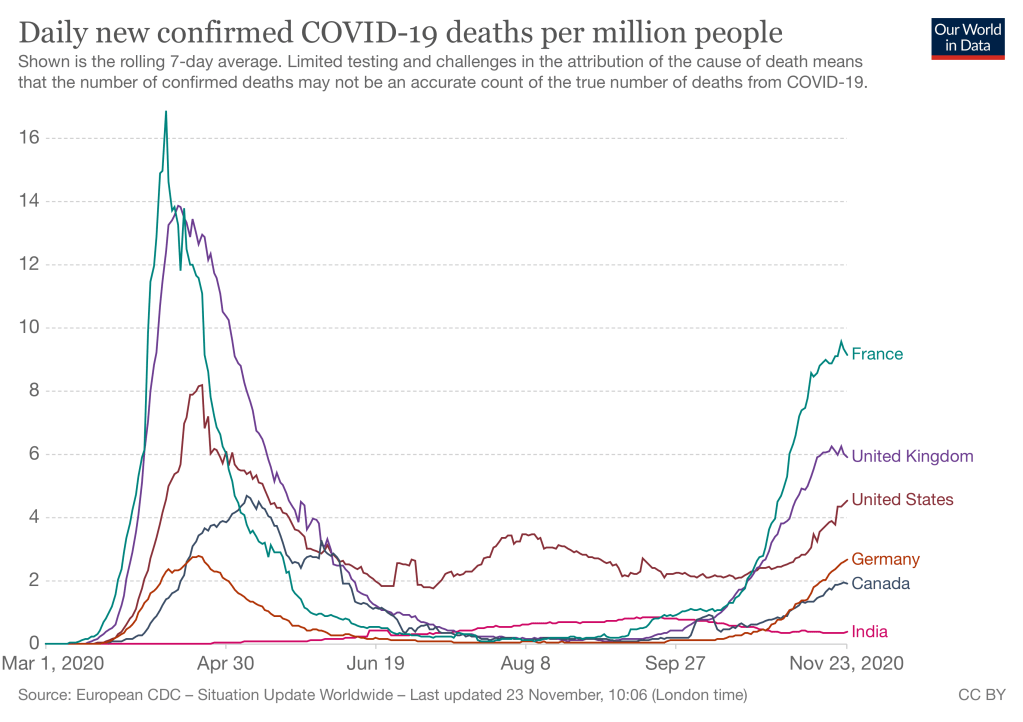
This is a follow-up to my discussion of high Covid incidence (cases per population) in Europe. As of Nov. 23, France has turned things around. Other European countries are at least not getting worse. The US is still growing rapidly. But new cases are still high in all of these countries, and they have a long way to go to return to the low rates of the Summer. China, Korea, and Taiwan are still invisibly low by comparison.
Deaths increased in October/November less dramatically than cases, reflecting large improvements in treatment of serious Covid. Deaths lag cases by approximately 2 weeks, which may explain why France’s recent turnaround in infection rates does not show up yet.
The last figure is supposed to show today’s data from Our World In Data, but WordPress seems to have trouble rendering it.
For much of the Covid-19 pandemic, the USA was the worst off by many measures. Total number of cases, number of deaths, incidence rate (new cases per capita) — we were the highest large country on all of them.
That is no longer true, to my surprise. Much of Europe is now as badly off as we are. The relevant comparison is per capita, in order to adjust for country size. I selected 4 large European countries: Italy, France, UK, and Germany. Three are now in the same range of misery, although Germany has been consistently a bit better. This figure shows daily incidence. (New cases per day.)
Another doctor has recently used parachutes as an example of why some medical treatments don’t need to be tested before using them on patients. That historical claim is wrong.
Arguing for “The search for perfect evidence may be the enemy of good policy,” Greenhalgh, a physician and expert in health care delivery at the University of Oxford, fumed in the Boston Review. “As with parachutes for jumping out of airplanes, it is time to act without waiting for randomized controlled trial evidence.”[emphasis added]….
COVID-19, she argues, has revealed the limits of evidence-based medicine—masks being a potent case in point.
The United Kingdom’s mask crusader Ellen Ruppel Shell Science 16 Oct 2020: Vol. 370, Issue 6514, pp. 276-277 DOI: 10.1126/science.370.6514.276
A 2003 article in British Medical Journal claimed after a literature search that “No randomised controlled trials of parachute use have been undertaken,[sic]” and went on to claim that “Individuals who insist that all interventions need to be validated by a randomised controlled trial need to come down to earth with a bump.” This is nonsense. Parachutes were heavily tested by the British air force late in WW I, for example. The issue was controversial at the time because German pilots already had parachutes, and the British military was slow to adopt, perhaps because of NIH (Not Invented Here). Continued trials delayed deployment until after the war was over.
Jet ejection seats, a “super-parachute” invented in the 1940s, received comprehensive engineering tests as various designs were experimented on. Tests ultimately included multiple human trials with volunteers. Despite that, many pilots at the time were hesitant to trust them, but field experience (and lack of alternatives when you were about to crash) led to still-reluctant acceptance. The reluctance stemmed from the dangers of ejection – severe injuries were common, due to high accelerations, collisons with pieces of the aircraft, and so forth. Continued experimentation at many levels (simulations, scale models, dummy pilots, etc.) have led to many improvements over the early designs, and most pilots who eject now are not permanently injured.
Test of a 0/0 ejection by Major Jim Hall, 1965
So parachutes have been, and new designs continue to be, heavily tested. Perhaps the 2003 authors missed them because they did not search obscure engineering and in-house journals written decades before the Internet. What about the “controlled” part of Randomized Controlled Trials? They had not even been invented in 1918; R.A. Fisher’s seminal work on experimental statistics was done in the 1920s and 30s.
More important, engineering trials have something better than randomization: deliberate “corner tests.” With humans and diseases we don’t know all the variables that affect treatment effectiveness, and even if we knew them, we couldn’t measure many of them. But with engineered systems we can figure out most key variables ahead of time. So trials can be run with:
Low pilot weight / high pilot weight
Low airspeed/high airspeed
Low, intermediate, and high altitudes
Aircraft at 0 pitch and yaw, all the way to aircraft inverted.
Delayed or early seat ejection.
Testing prototypes (and now, finite element simulations) can tell us which conditions are most extreme, so not all corners need full-scale tests.
Of course some of these tests will “fail,” e.g. early ejection seats did not work at low altitude and airspeed. Those limits are then written into pilots’ manuals. That is considerably better than we do with many RCT’s, which deliberately choose trial subjects who are more healthy than patients who will ultimately take the medicine.
So let’s stop using this analogy. Parachutes were never adopted without (the equivalent of) RCTs. Thereare many reasons to adopt masks without years of testing, but this is not one of them.
(I have written more about this in my book draft about the evolution of flying from an art to a science.)
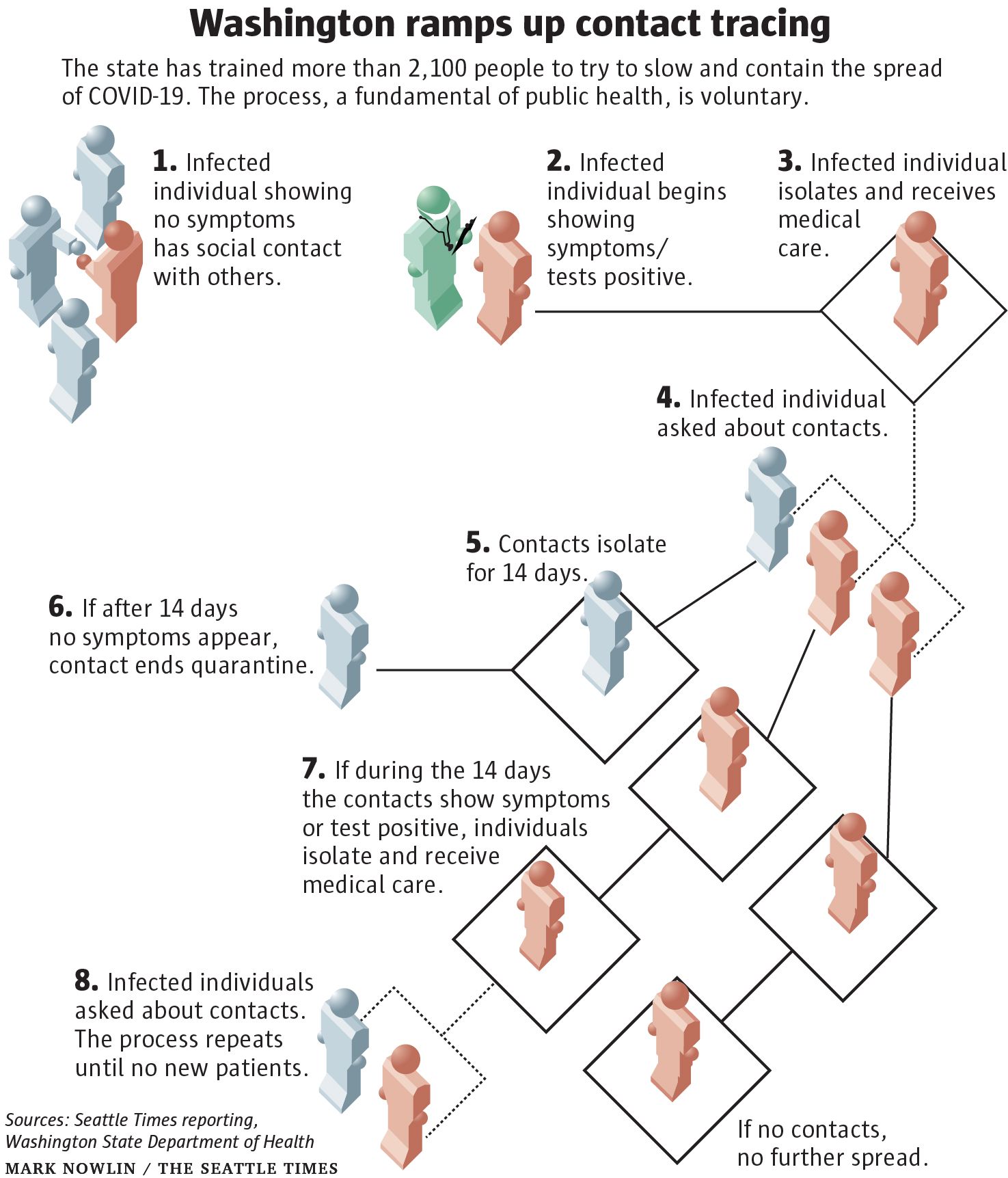
You cannot trace everybody, so be smart about who you trace. This article points out the impracticality of massive contact tracing, and how to build a learning system to make it useful anyway. Contact tracing is hard, and when there are too many cases it starts to break down. But we need to figure it out, especially in high-priority settings and in places with limited outbreaks. There are also many idiosyncrasies in Covid infection patterns. A well-executed learning system can gradually make smarter judgments about where to look for cases, who to test, who to quarantine, and when to lift the quarantine.
As we build our nation’s tracing operations, we need to ensure that they are effective at identifying contacts while attempting to quarantine as few people as possible, for as short a duration as possible. To ensure contact tracing remains viable at scale, we must develop data-driven metrics to evaluate and adapt our contact tracing efforts. Historically, successful contact tracing has been measured by its sensitivity [based on more is better]. However, at scale “more is better” breaks down. We must have corresponding metrics for specificity, to … exclude from quarantine those people who have not themselves become carriers of the virus.
But will America’s current political decision-making paralysis, chaos, and suspicion allow the systematic tracing program that would be required? At the national level it seems unlikely. But this approach can be done by states or smaller units. There are probably some states with enough leadership and public willingness to be serious about suppressing Covid before it wipes out another 6 months of jobs and education!
The first microprocessor is almost 50 years old, but microprocessors (MPUs) continue to revolutionize new areas. (First MPU = Intel 4004, in 1971, which Intel designed for a calculator company!) In concert with Moore’s Law and now ubiquitous wireless two-way wireless data transmission (thanks, Qualcomm!). smartphones have become a basic building block of many products.
A companion to explain what’s in your air, anywhere. Flow is the intelligent device that fits into your daily life and helps you make the best air quality choices for yourself, your family, your community.
Here is a quick review I wrote of the “Flow” pollution meter, after using it for a few months. I wrote it as a comment on a blog post by Meredith Fowlie about monitoring the effects of fires in N. California.
America’s health care research system has many problems. The overall result is poor return on the money spent. The lure of big $ is a factor in many of them. Two specific problems:
What gets research $ (including from Federal $) is heavily driven by profit potential, not medical potential. Ideas that can’t be patented get little research.
Academic career incentives distort both topics of research (what will corporate sponsors pay for?) and publication. The “replicability crisis” is not just in social sciences.
This NYT article illustrates one way that drug companies indirectly manipulate research agendas: huge payments to influential researchers. In this article, Board of Directors fees. Large speaking fees for nominal work are another common mechanism. Here are some others:
Drugmakers don’t just compromise doctors; they also undermine top medical journals and skew medical research. By Harriet A. Washington | June 3, 2011
I could go on and on about this problem, partly because I live in a biotech town and work at a biotech university. I have posted about this elsewhere in this blog. But since it’s not an area where I am doing research, I will restrain myself.
How can researchers maximize learning from experiments, especially from very expensive experiments such as clinical trials? This article shows how a Bayesian analysis of the data would have been much more informative, and likely would have saved a useful new technique for dealing with ARDS.
I am a big supporter of Bayesian methods, which will become even more important/useful with machine learning. But a colleague, Dr. Nick Eubank, pointed out that the data could also have been re-analyzed using frequentist statistics. The problem with the original analysis was not primarily that they used frequentist statistics. Rather, it was that they set a fixed (and rather large) threshold for defining success. This threshold was probably unattainable. But the clinical trial could still have been “saved,” even by conventional statistics.
Here is a draft of a letter to the editor on this subject. Apologies for the very academic tone – that’s what we do for academic journals!
The study analyzed in their article was shut down prematurely due to the unlikelihood that it would attain the target level of performance. Their paper shows that this might have been avoided, and the technique shown to have benefit, if their analysis had been performed before terminating the trial. A related analysis could usefully have been done within the frequentist statistical framework. According to their Table 2, a frequentist analysis (equivalent to an uninformative prior) would have suggested a 96% chance that the treatment was beneficial, and an 85% chance that it had RR < .9 .
The reason the original study appeared to be failing was not solely that it was analyzed with frequentist methods. It also failed because the target threshold for “success” was set at a high threshold, namely RR < .67. Thus, although the full Bayesian analysis of the article was more informative, even frequentist statistics can be useful to investigate the implications of different definitions of success.
Credit for this observation goes to Nick. I will ask him for permission to include one of his emails to me on this subject.