Not just another cell-phone idea
Can Contact Tracing Work At COVID Scale? Amit Kaushal and Russ B. Altman JULY 8, 2020 10.1377/hblog20200630.746159
You cannot trace everybody, so be smart about who you trace. This article points out the impracticality of massive contact tracing, and how to build a learning system to make it useful anyway. Contact tracing is hard, and when there are too many cases it starts to break down. But we need to figure it out, especially in high-priority settings and in places with limited outbreaks. There are also many idiosyncrasies in Covid infection patterns. A well-executed learning system can gradually make smarter judgments about where to look for cases, who to test, who to quarantine, and when to lift the quarantine.
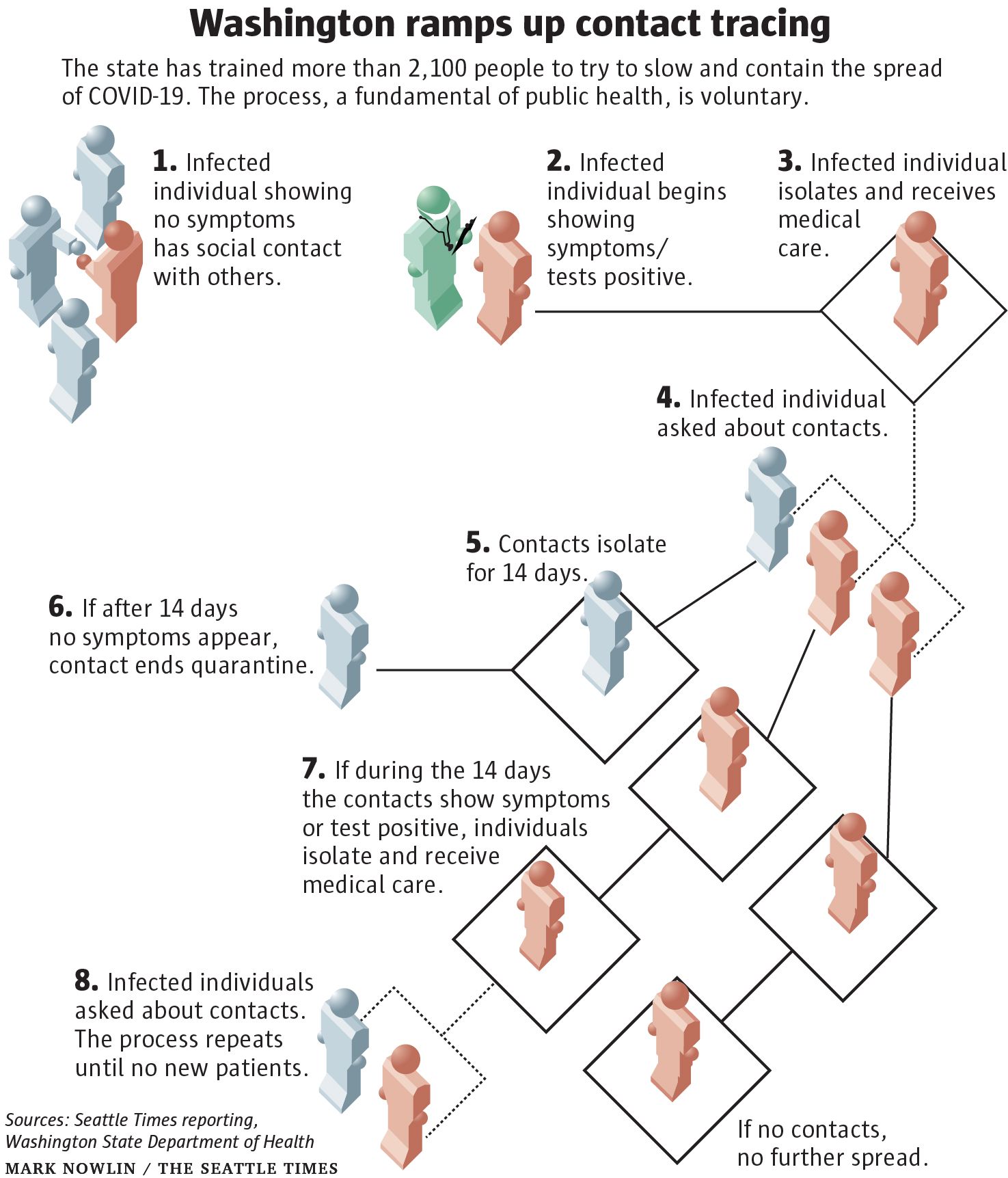
As we build our nation’s tracing operations, we need to ensure that they are effective at identifying contacts while attempting to quarantine as few people as possible, for as short a duration as possible. To ensure contact tracing remains viable at scale, we must develop data-driven metrics to evaluate and adapt our contact tracing efforts. Historically, successful contact tracing has been measured by its sensitivity [based on more is better]. However, at scale “more is better” breaks down. We must have corresponding metrics for specificity, to … exclude from quarantine those people who have not themselves become carriers of the virus.
Can Contact Tracing Work At COVID Scale? | Health Affairs
But will America’s current political decision-making paralysis, chaos, and suspicion allow the systematic tracing program that would be required? At the national level it seems unlikely. But this approach can be done by states or smaller units. There are probably some states with enough leadership and public willingness to be serious about suppressing Covid before it wipes out another 6 months of jobs and education!





