Bilge from a right-wing pseudo-intellectual. I’ve never heard of this guy before, but he seems to be an expert in deception rather than analysis.
As it’s Davos time, Oxfam has issued its traditional demand for a handout. Their wealth report this year informs us that a mere eight people have more wealth than the bottom 50 percent of the world’s population. This is entirely true of course. But Oxfam’s solution is that we should take it from the rich and […]Source: Why Oxfam is getting it wrong about poverty – CapX
This is an example of deceptive reasoning. Here’s my quick analysis:
Worstall writes:
>The result is that entrepreneurs get to keep some 3 per cent of the value of their creations. The other 97 per cent of the value flows to us consumers out here.
….
>Poverty exists and obviously we’d prefer that it didn’t. That’s why we need more rich people not fewer: because we need someone to create value for the rest of us to consume.
So he is equating “rich people” to “entrepreneurs” to “creators of value.” If only that were true. Although a small number of tech entrepreneurs get most of the publicity (Steve Jobs, Bill Gates, etc), most of the giant corporate profits are coming from increasing market power/decreasing competition in many markets. For example, few outside the industry think that the “financial services” industry (e.g. investment banking) creates value comparable to the huge profits it makes.
He is also using misdirection to imply that Sam Walton’s heirs were the entrepreneurs who created Walmart’s economic value!
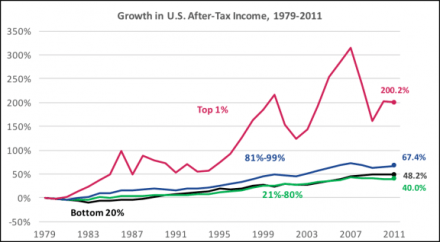
Finally, he keeps using a “3 percent” number to imply that “the masses” get 97 percent of increasing economic value, and the ultra-rich get only 3 percent. In fact median income has not grown for several decades. While the overall GDP has doubled in the last 30 years, the extra income has gone entirely to the upper ten percent. (Median household income rose by 8% in the last 30 years.)
Sources: http://www.multpl.com/us-gdp-inflation-adjusted/table
https://fred.stlouisfed.org/series/MEHOINUSA672N
A slightly different way of measuring. Compare black and red lines.
So the blog post is a dishonest piece of fallacious reasoning. Is this typical of the Adam Smith Institute, where he is apparently based? Is this the average reasoning level of right-wing intellectuals today?
By the way, I’m sure there are problems with Oxfam’s report – just not the ones he claims.
 A related dream is modularity without sacrificing performance. This has been discussed for cell phones for many years, although in the past I have been skeptical. This article, though, sounds as if Motorola has a chance at doing both. Technically, it sounds like a good concept, if they can pull it off as well as the article suggests. Of course, technical excellence is never sufficient to become a standard. And Motorola, with all its ownership turmoil in recent years, is not very credible. But I’m heartened to think that the goal of a modular smartphone may be technically realistic, which would be great for consumers. (It’s important that Moto is not talking about creating a new operating system or app platform. Just look at Nokia and Microsoft to see how hard that is.)
A related dream is modularity without sacrificing performance. This has been discussed for cell phones for many years, although in the past I have been skeptical. This article, though, sounds as if Motorola has a chance at doing both. Technically, it sounds like a good concept, if they can pull it off as well as the article suggests. Of course, technical excellence is never sufficient to become a standard. And Motorola, with all its ownership turmoil in recent years, is not very credible. But I’m heartened to think that the goal of a modular smartphone may be technically realistic, which would be great for consumers. (It’s important that Moto is not talking about creating a new operating system or app platform. Just look at Nokia and Microsoft to see how hard that is.)